SQL Server
-
 批量为数据库表设置IDENTITY_INSERT ON(开启增长列插入)
批量为数据库表设置IDENTITY_INSERT ON(开启增长列插入)在SQL Server中,如果需要在自增长列插入值,我们必须手动执行 SET IDENTITY_INSERT 表名 ON 命令,方能进行数据插入操作。但是如果我需要为整个数据库的表执行该操作呢? 特别是数据库中还有部分表不存在自增长列的情况下!
-
SQL Server(MSSQL)批量删除外键及表的T-SQL脚本
有时我们要删除数据库中指定表的时候,却发现错综复杂的外键让我们无从下手。或者要一次删除大量表,不得一次一次重复进行大量手工操作。
-
SQL Server如何在IN条件时使用参数查询
常规情况下,如果使用IN条件查询数据时,应避免使用参数化查询.但是有时,我们却遇某些特殊情况,必须在有参数的情况下使用in,怎么办?
-
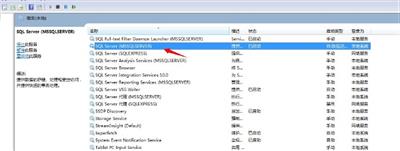 SQL Server启动故障分析及解决技巧
SQL Server启动故障分析及解决技巧目前SQL Server数据库作为微软一款优秀的RDBMS,其本身启动的时候是很少出问题的,我们在平时用的时候,很少关注起启动过程,或者很少了解其底层运行过程,大部分的过程只关注其内部的表、存储过程、视图、函数等一系列应用方式,而当有一天它运行的正常的时候突然启动不起来了,这时候就束手无策了,能做的或许只能是重装、配置、还原等,但这一个过程其实是一个非常耗时的过程,尤其当我们面对是庞大的生产库的时候,可能在这火烧眉毛的时刻,是不允许你再重搭建一套环境的。 所以作为一个合格的数据库使用者,我们要了解其启动、运行过程的事情,一旦发生问题,我们也能及时定位,迅速解决。
-
MSSQL批量删除数据库指定表
有时候因为一些原因,需要批量删除数据库的表,如果手动一个一个的删就太麻烦了,假如表之间还存在主外键,这绝对是苦差事,不过没有关系,我们可以自己写个游标,先批量清除外键,再删除所有表。
-
 SQLServer性能优化使用nolock提升查询性能
SQLServer性能优化使用nolock提升查询性能公司数据库随着时间的增长,数据越来越多,查询速度也越来越慢。进数据库看了一下,几十万调的数据,查询起来确实很费时间。 要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑。其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能。不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成Dirty Read,就是读到无效的数据。
-
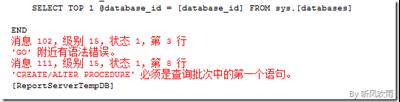 SQL Server 在多个数据库中创建同一个存储过程(Create Same Stored Procedure in All Databases)
SQL Server 在多个数据库中创建同一个存储过程(Create Same Stored Procedure in All Databases)在我的数据库服务器上,同一个实例下面挂载着许多相同结构的数据库,他们为不同公司提供着服务,在许多时候我需要同时创建、修改、删除一些对象,存储过程就是其中一个,但是想要批量创建存储,这有些特殊,下面就教你如何实现在多个数据库中创建同一个存储过程(Create Same Stored Procedure in All Databases)。